
学习yolo5算法
分割线
一、寻找数据集
在此之前我已经将yolo5的环境装配好了。下面就开始训练模型
训练模型第一步应该干什么呢?
找数据!!!
数据无价,最后在我的几经筛选之下,找到了这个数据
https://www.kaggle.com/datasets/tuyenldvn/falldataset-imvia
有关检测跌倒的数据,10G开下。
下载下来发现数据集全是视频和txt文档,文档经过我的查阅是记录跌倒的时间帧和方位。
以video(1).avi为例,
前两行:48 和 80 通常表示该视频跌倒事件的开始帧与结束帧(可根据官方文档或 README 确认)。
后续每行:frame_index, class_id, x_min, y_min, x_max, y_max。
- 例如
5,1,292,152,311,240表示第5帧、类别为1、**左上角(292,152)、右下角(311,240)**。
二、处理数据集
需要将每个视频拆分成视频帧,我们就以每秒25帧来切割,正好我的电脑上就有ffmepg,我就用了命令
ffmpeg -i "video (1).avi" -r 25 frames_%04d.jpg |
但是视频的数量也太多了,所以我又写了一个批处理的来处理文件里的所有同类视频
@echo off |
下一步开始使用yolo5训练
三、疑问
发现数据集中的数据存在一定的问题。查阅readme文档也没有定义。readme文档中说有关数据集的文档中存储的数据依次为:
帧,框高,框宽,框的中心坐标。
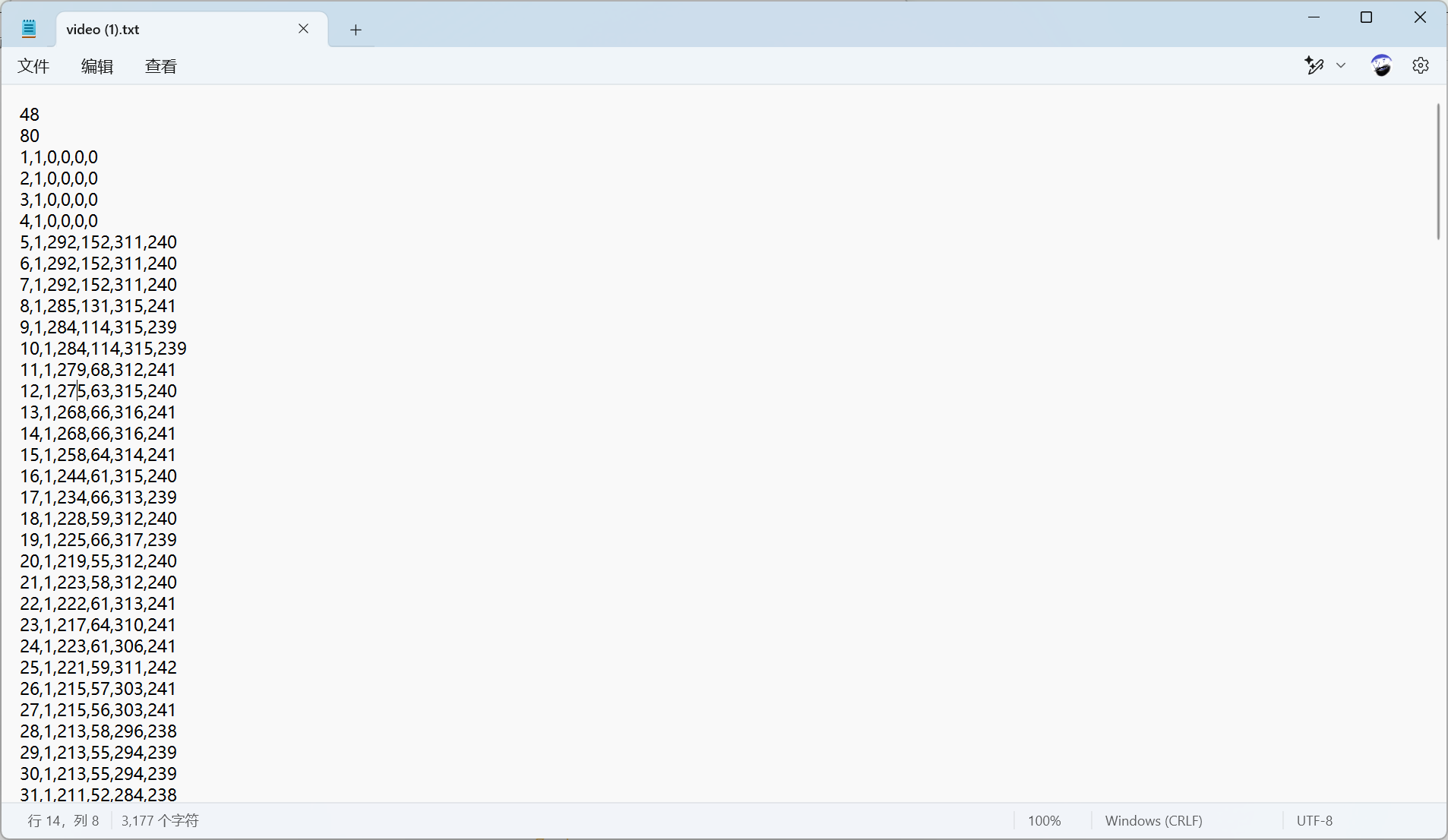
以一为例,数据中一行出现了6个数据,我理解为
帧编号,未知,框高,框宽,中心坐标
未知:我觉得是状态显示
- 1——normal(正常)
- 8——fall(摔倒)
- 7——(倒地)
但是存在问题我在下面好几个文档中发现了1、2、3、4
以下是我猜测
- 2——应当为跌倒的过程
- 4——应当为侧躺在地上
- 5——应当为平趴在地上
这些只是假设。
先不管状态对应的什么意思,我们先把数据处理成yolo格式的,进行归一化处理。
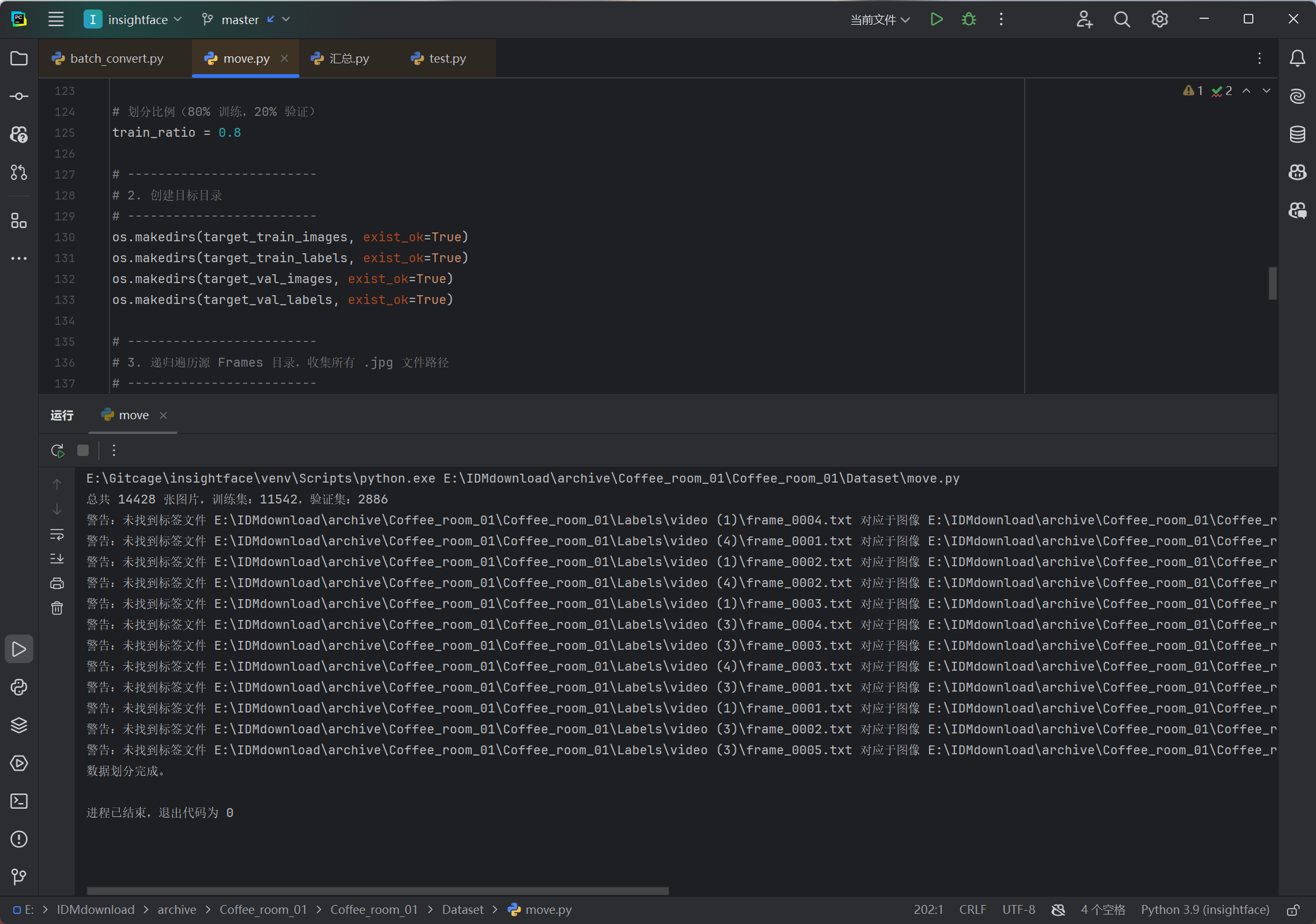
划分数据集,下一步进行yolo训练
train: E:\IDMdownload\archive\Coffee_room_01\Coffee_room_01\Dataset\train\images |
撰写yaml的文件,方便yolo推理
下一步开始推理
python train.py --img 320 --batch 16 --epochs 50 --data fall.yaml --weights yolov5s.pt |
下面详细解读一下命令:
python train.py --img 320 --batch 16 --epochs 50 --data fall.yaml --weights yolov5s.pt |
1. python train.py
- 这是运行 YOLOv5 训练脚本的入口文件。
train.py是 YOLOv5 提供的训练脚本,负责加载数据、构建模型、进行训练并保存权重。
2. 参数 --img 320
- 指定输入图像的尺寸为 320×320(YOLOv5 会将原始图像按比例缩放到该尺寸)。
- 如果原始图像分辨率为 320×240,也可以用 320 作为短边尺寸。一般建议选择与训练数据相似的尺寸以兼顾计算效率和细节保留。
3. 参数 --batch 16
- 指定每个训练批次(batch)的图片数为 16。
- 批次大小与 GPU 显存有关:RTX 3070 通常能够支持 16 的 batch size;如果显存不足可以减小该值。
4. 参数 --epochs 50
- 表示整个训练过程中遍历整个数据集 50 轮(epoch)。
- 训练轮数决定了模型训练的充分程度,初次实验可以设置 50 轮,之后根据验证集表现和收敛情况再做调整。
5. 参数 --data fall.yaml
指定数据集的配置文件为
fall.yaml。该 YAML 文件通常包含以下信息:
train和val两个路径,分别指向训练集和验证集的图片目录(例如:Dataset/images/train和Dataset/images/val)。names
字段:定义所有类别的名称,例如:
```yaml
names:
0: "state_1"
1: "state_7"
2: "state_8"
3: "state_2"
4: "state_3"
5: "state_4"
6: "state_5"确保 YAML 文件的格式和路径与实际数据集结构一致。
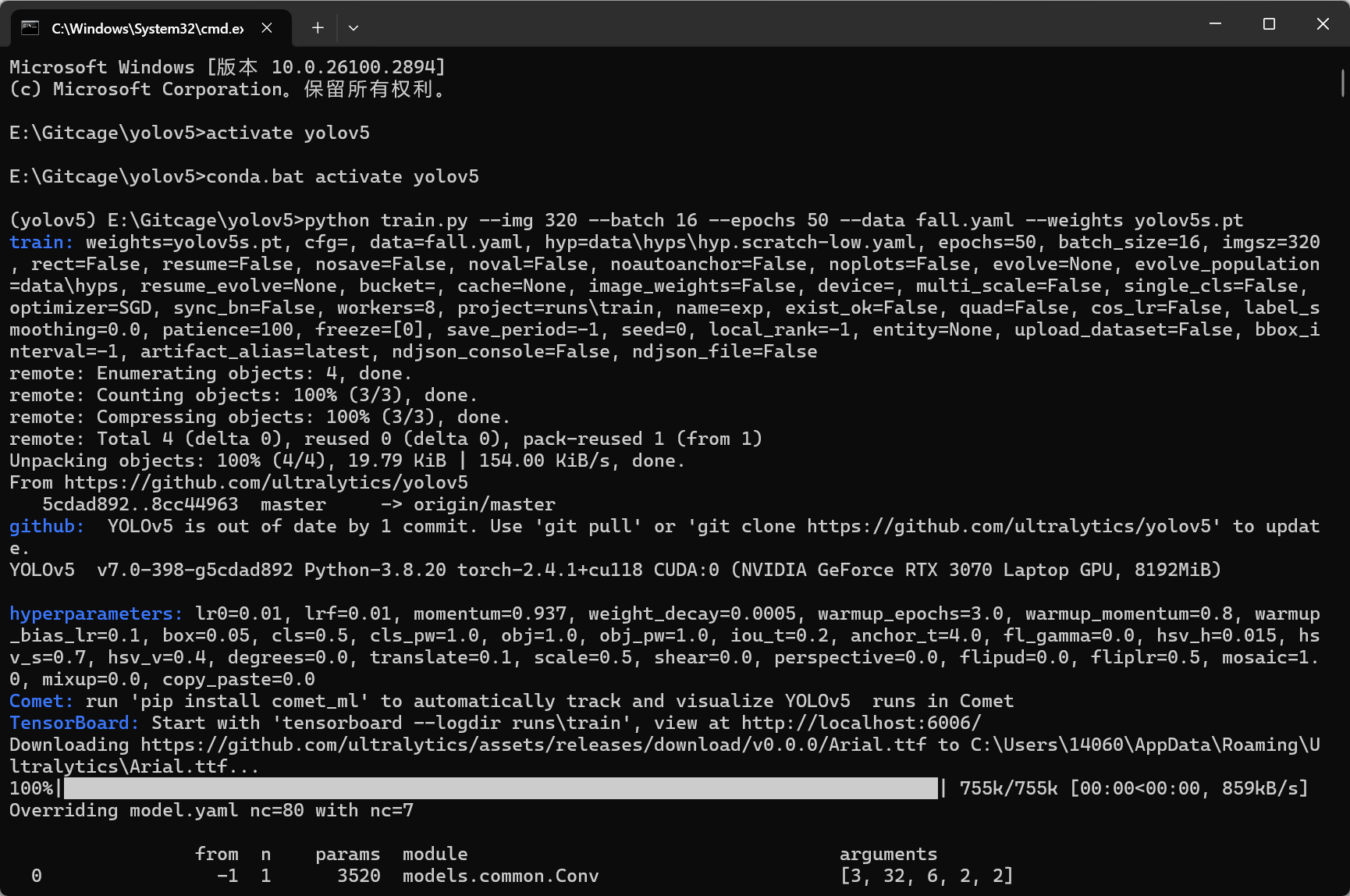
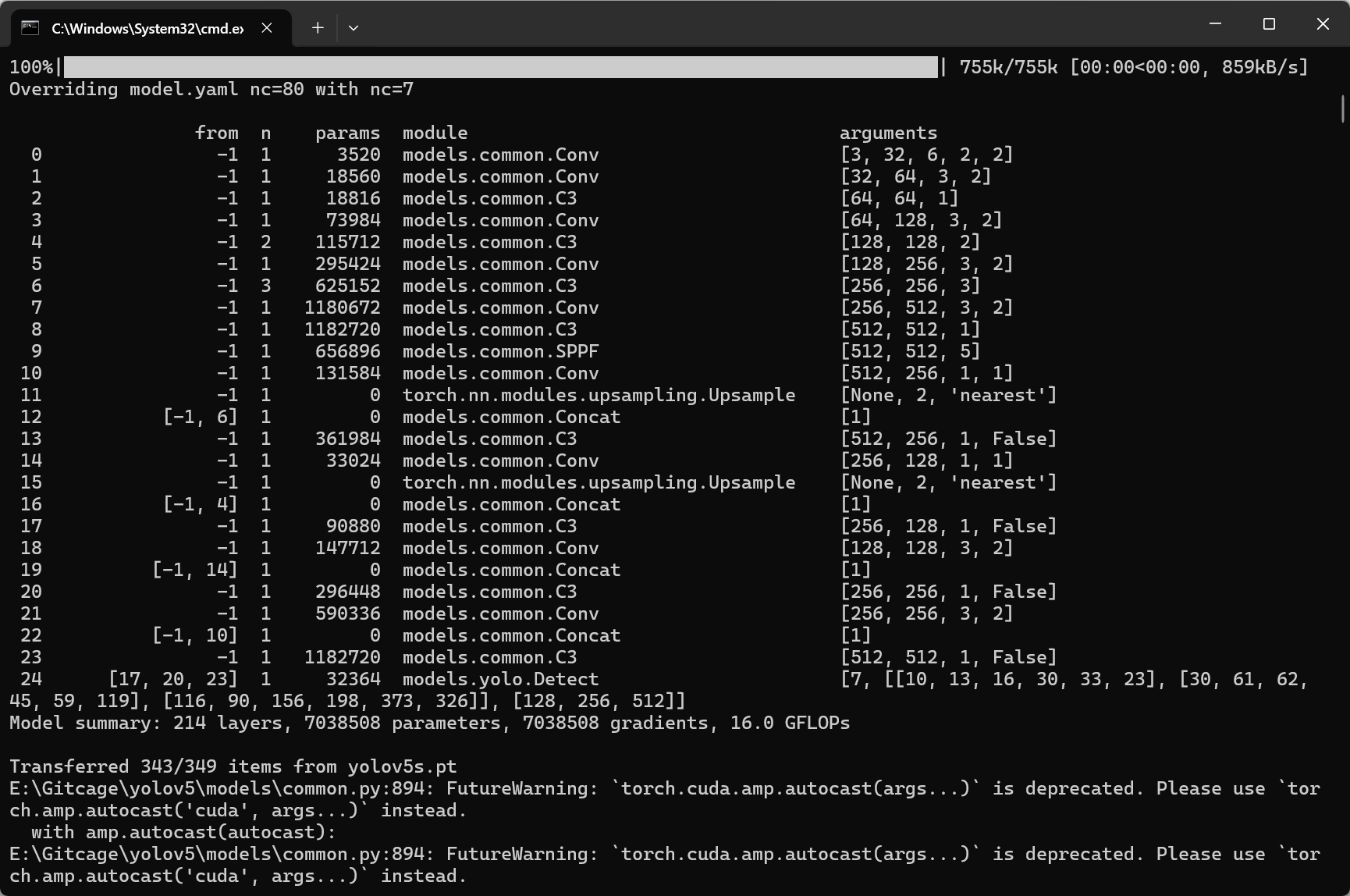
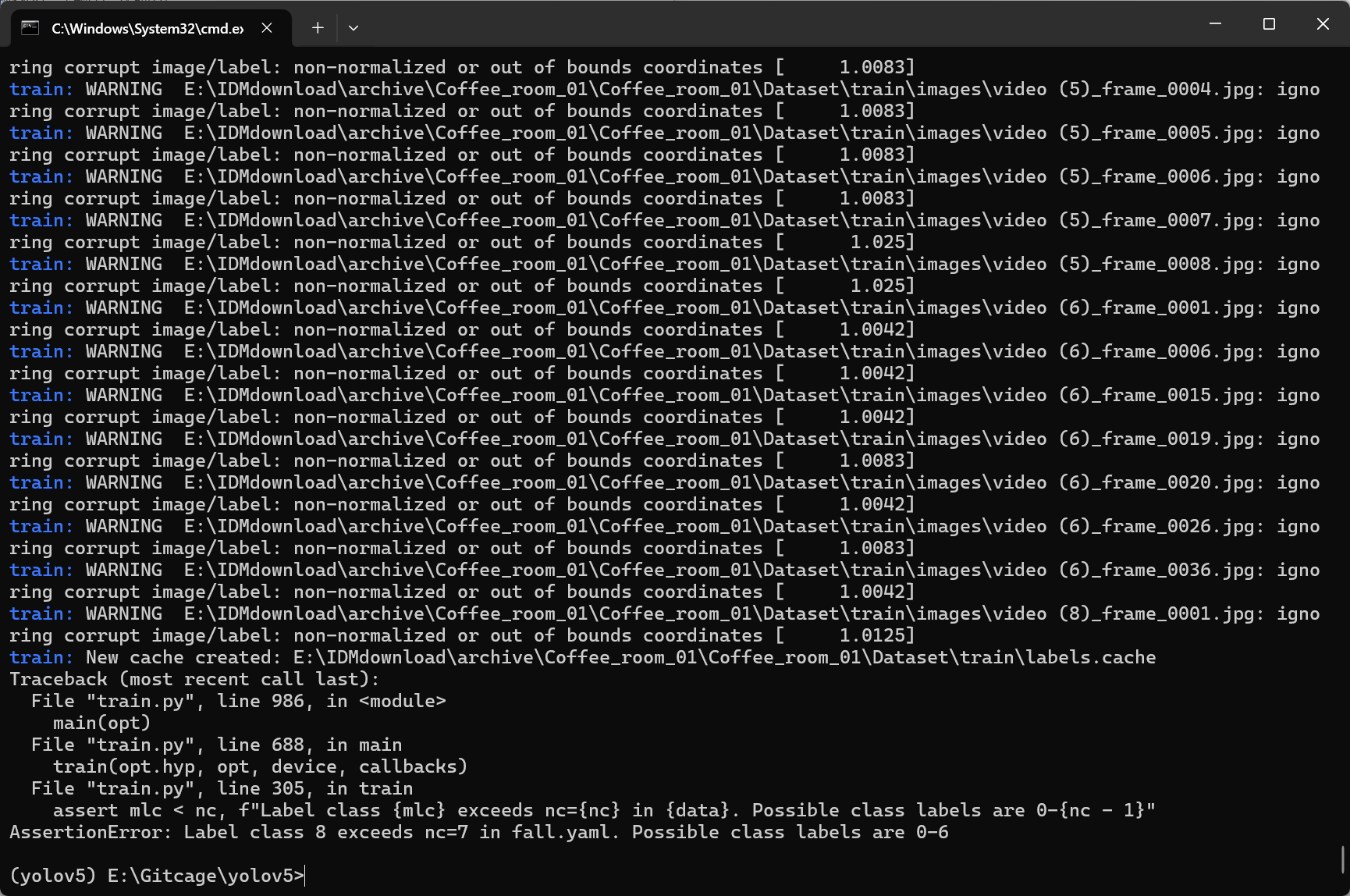
很遗憾,报错了,状态映射不对。
train: E:\IDMdownload\archive\Coffee_room_01\Coffee_room_01\Dataset\train\images |
四、处理错误
1.在训练时,YOLOv5 检查到部分图片对应的标签文件中的坐标数据存在问题,具体问题是“non-normalized or out of bounds coordinates”(未归一化或超出边界的坐标)。
1. 什么是“non-normalized or out of bounds coordinates”
归一化坐标要求:
YOLO 格式要求标签中的坐标值必须归一化到 [0, 1] 范围内。也就是说,x_center、y_center、宽度和高度的值都应该是图像宽度和高度的比例,而不是绝对像素值。超出边界:
如果标签中的归一化坐标超过了 1 或小于 0(比如 1.2167 或 1.0042),则表示目标框的坐标计算有误或者没有进行正确归一化。确保在转换标签时,对所有边界框的中心坐标和宽高都进行了归一化处理。例如,如果图像尺寸为 320×240,那么中心坐标应除以 320 和 240,宽度和高度也应除以对应尺寸。
检查转换脚本,确保计算公式正确:
x_center_norm = center_x / IMG_WIDTH
y_center_norm = center_y / IMG_HEIGHT
width_norm = box_width / IMG_WIDTH
height_norm = box_height / IMG_HEIGHT
标签文件数值看起来并不是“框高、框宽、中心坐标”,而更像是“框左上角和右下角的坐标”。例如,对于行
5,1,292,152,311,240 |
如果解释为:
- frame_number = 5
- state = 1
- x_min = 292, y_min = 152
- x_max = 311, y_max = 240
那么:
- 计算框宽 = 311 – 292 = 19
- 计算框高 = 240 – 152 = 88
- 中心坐标 = ((292+311)/2, (152+240)/2) = (301.5, 196)
归一化后:
- x_center_norm = 301.5 / 320 ≈ 0.942
- y_center_norm = 196 / 240 ≈ 0.8167
- width_norm = 19 / 320 ≈ 0.0594
- height_norm = 88 / 240 ≈ 0.3667
这就符合要求,不会超过 1。而目前的转换函数直接把第三、四列当作 box_height 和 box_width、第五、第六列当作中心坐标计算归一化,结果就会出现 292/240 ≈ 1.2167 这样的数值,从而导致“non-normalized or out of bounds coordinates”的错误。
因此,需要修改转换函数,使其先根据 x_min、y_min、x_max、y_max 计算出中心坐标和宽高,再归一化。
下面是修改后的完整代码,重点在于更新转换函数以及处理标签文件时的字段解释:
import os |
详细解读
路径配置部分
annotations_dir指标签文件所在目录。frames_root_dir指向视频帧所在的根目录(每个视频的帧文件夹命名如 “video (N)_frames”)。output_labels_root指向输出的转换后标签存放目录(每个视频输出到 “video (N)” 文件夹中)。
图像尺寸
- 根据 Le2i 数据集设置为 320×240。
转换函数
convert_bbox_from_corners- 新函数接受 x_min, y_min, x_max, y_max 四个值,并计算:
- 框宽 = x_max - x_min
- 框高 = y_max - y_min
- 中心坐标 = ((x_min + x_max) / 2, (y_min + y_max) / 2)
- 然后归一化各值。
- 新函数接受 x_min, y_min, x_max, y_max 四个值,并计算:
处理单个标签文件函数
- 根据文件名确定视频文件夹名称(如 “video (1)”),然后构造视频帧文件夹路径(
Frames\video (1)_frames)和输出标签文件夹路径(Labels\video (1))。 - 判断标签文件格式:如果第一行只包含一个数字,则跳过前两行,否则所有行都是记录。
- 逐行解析后,根据 x_min, y_min, x_max, y_max 计算 YOLO 格式的归一化坐标,写入对应帧图像的标签文件。
- 根据文件名确定视频文件夹名称(如 “video (1)”),然后构造视频帧文件夹路径(
批量处理部分
- 使用 glob 递归查找所有以 “video” 开头的标签文件,然后逐个调用
process_annotation_file处理。
- 使用 glob 递归查找所有以 “video” 开头的标签文件,然后逐个调用
将以上代码保存为
batch_convert.py。在命令行中运行:
python batch_convert.py
脚本会输出处理情况,并在输出目录下生成转换后的 YOLO 格式标签文件。
2.Label class 8 exceeds nc=8
直接使用原始标签(即 1 到 8),那么你需要调整 YOLO 数据配置文件,使得允许的类别范围覆盖这些数字。YOLOv5 要求标签数字必须在 0 到 nc-1 内。如果标签中出现 1 到 8,则需要将类别数量设置为 9,并在 names 中提供 9 个条目。
一种常见的做法是:
- 把索引 0 作为占位符(因为你的数据中没有标签 0),然后索引 1 到 8 分别对应你的 8 个状态。
例如,可以修改 fall.yaml 文件如下:
train: E:\IDMdownload\archive\Coffee_room_01\Coffee_room_01\Dataset\train\images |
这样,训练时有效标签就是 1 到 8(共 8 个类别),并且标签数字均在 0 到 8 的范围内(虽然索引 0 不会出现在数据中)。这种方法避免了在预处理阶段做减一操作,同时满足 YOLOv5 的要求。
请注意:
- 需要确保数据中的标签都是在 1 到 8 之间。
- 如果以后确认了每个状态的具体意义,也可以对
names中的名称进行相应修改。
这样修改后,训练时就不会报错“Label class 8 exceeds nc=8”了,因为允许的类别范围是 0 到 8(即 9 个类别)。
五、训练情况
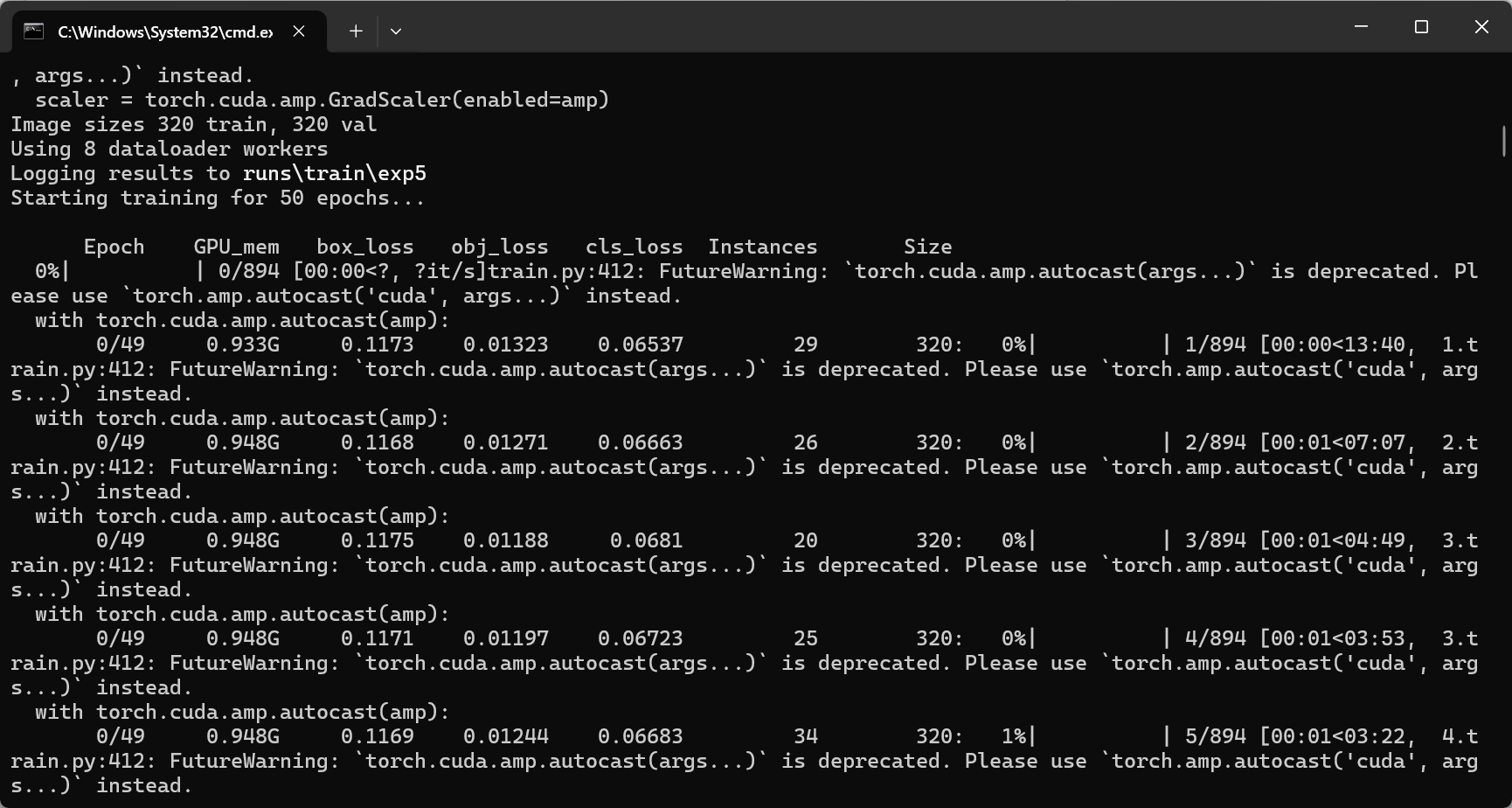
开始训练。
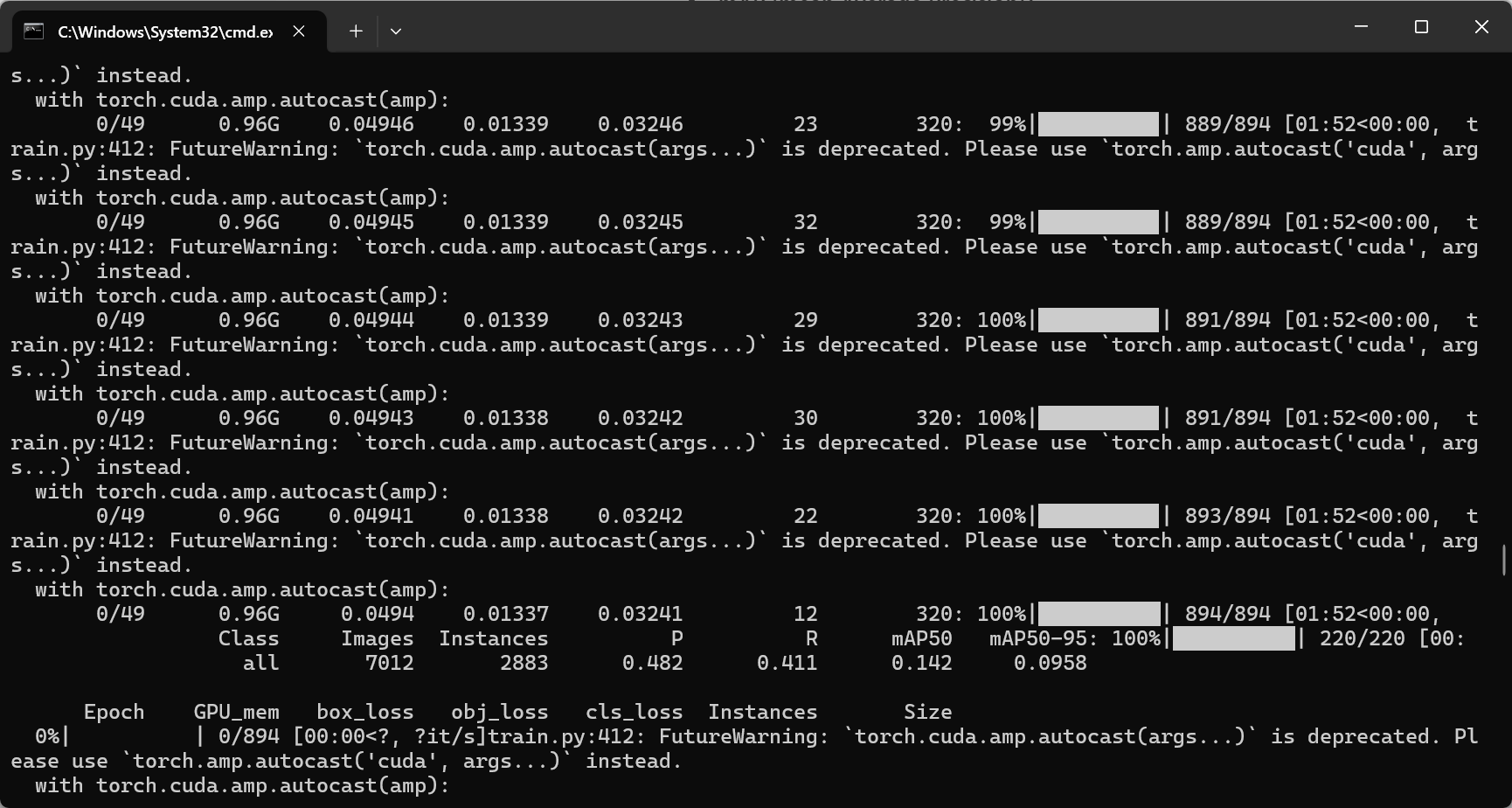
这段输出是 YOLOv5 在训练或验证阶段输出的性能指标和进度信息,我们来逐项解释:
1. 上半部分的输出
with torch.cuda.amp.autocast(amp): |
with torch.cuda.amp.autocast(amp):
这表示训练过程中启用了混合精度训练(Automatic Mixed Precision, AMP),利用 GPU 的半精度运算以加速训练并减少显存占用。- 后面跟着的进度条和数值(例如
0/49、0.96G等)通常表示当前 batch、当前进度、GPU 占用、损失值等信息。这部分内容根据具体版本和配置略有不同。
2. 后半部分的性能指标
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 220/220 [00: |
- Class:这里显示的是统计类别,“all” 表示所有类别的综合指标。
- Images:7012 表示总共参与评估的图片数量。
- Instances:2883 表示所有图片中目标实例的总数(例如,所有检测到的物体总数)。
- **P (Precision)**:0.482 表示精度为 48.2%。精度(Precision)反映了检测器预测的目标中有多少比例是真正的正确目标。
- **R (Recall)**:0.411 表示召回率为 41.1%。召回率(Recall)反映了所有真实目标中被检测到的比例。
- mAP50:0.142 表示在 IoU 阈值为 0.50 时,平均精度均值(mean Average Precision, mAP)为 14.2%。这意味着当预测框与真实框的 IoU 大于等于 0.50 时,模型的整体检测精度大约是 14.2%。
- mAP50-95:0.0958 表示在多个 IoU 阈值(从 0.50 到 0.95,通常以 0.05 为步长取平均)下计算的 mAP 值为 9.58%。这是更严格的指标,反映了模型在更高重叠要求下的性能。
总结
混合精度(AMP):利用
torch.cuda.amp.autocast实现混合精度训练,提高计算速度并降低显存占用。进度信息:训练或验证过程中显示了 GPU 占用、当前进度等。
性能指标
:
- 精度(P)约 48.2%,召回率(R)约 41.1%,
- mAP50(IoU≥0.50)约 14.2%,
- mAP50-95(多个 IoU 阈值的平均)约 9.58%。
这是第一轮的训练结果。还挺慢,需要等到五十轮结束看看指标。
测试结果
python detect.py --weights E:\Gitcage\yolov5\runs\train\exp5\weights\best.pt --source E:\IDMdownload\archive\Office\Office\video (1).avi --img 320 --conf 0.25 |
不是很理想,需要改进。

同时为了更美观的展示训练结果,
修改相关代码,将旧的调用方式替换为新版推荐的方式。例如,在 train.py(或 common.py 中)找到类似下面的代码:
with torch.cuda.amp.autocast(amp): |
将其修改为:
with torch.amp.autocast('cuda', enabled=amp): |
这样就能消除 FutureWarning。
等我整理完结果数据再展示吧。
现阶段我觉得训练的结果只有40%上下的精度,我觉得不够,我只用了这个数据集的一个文件夹进行训练。现在我尝试将四个文件夹的数据合并然后进行训练看看效果。
由原来的一万多张图片一下扩充到三万多张,期待。
新的训练代码记录一下。
python train.py --img 320 --batch 16 --epochs 50 --data bigfall.yaml --weights yolov5s.pt |
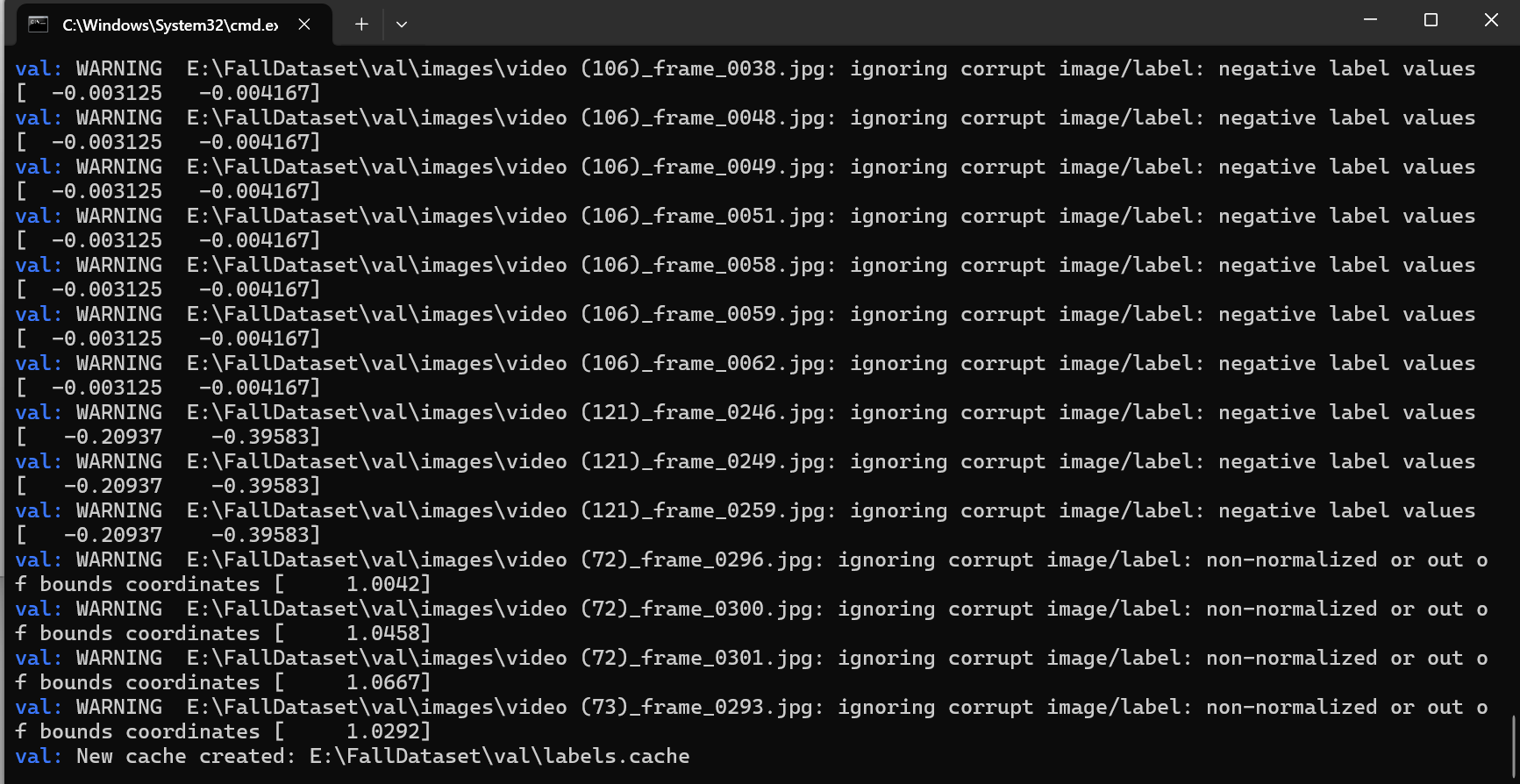
完了,出现数据集错误了,又白干了,又要重新查看数据集哪里错了
啊这。。。。
数据集出错也能训练的吗?
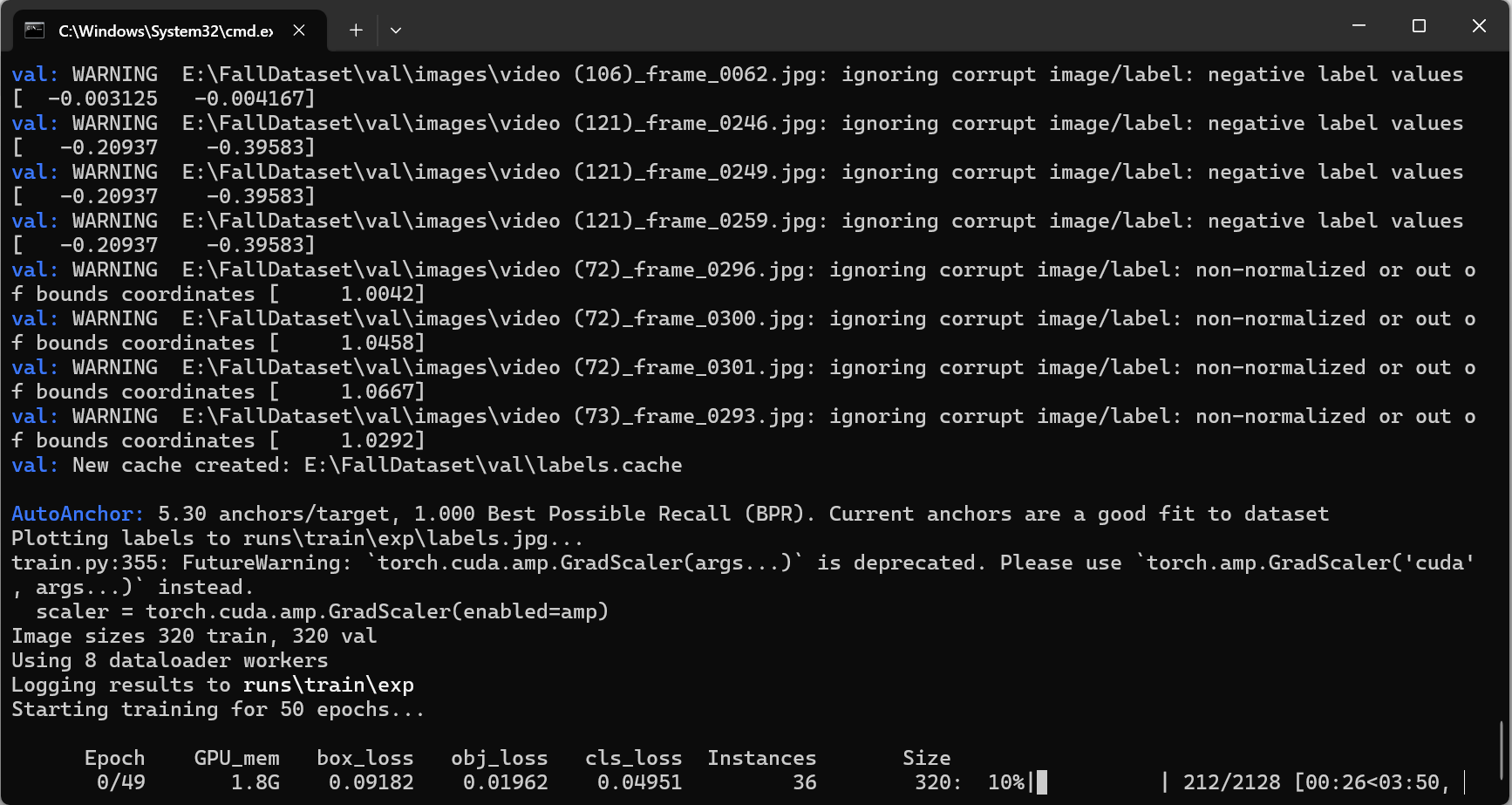
我先在这里记一下,100、106、121、72、73几个视频都存在数据处理问题。
简单筛查了一下发现是数据集没有配对上,等我把数据对其看看具体是哪里有问题。
yolov5训练结果
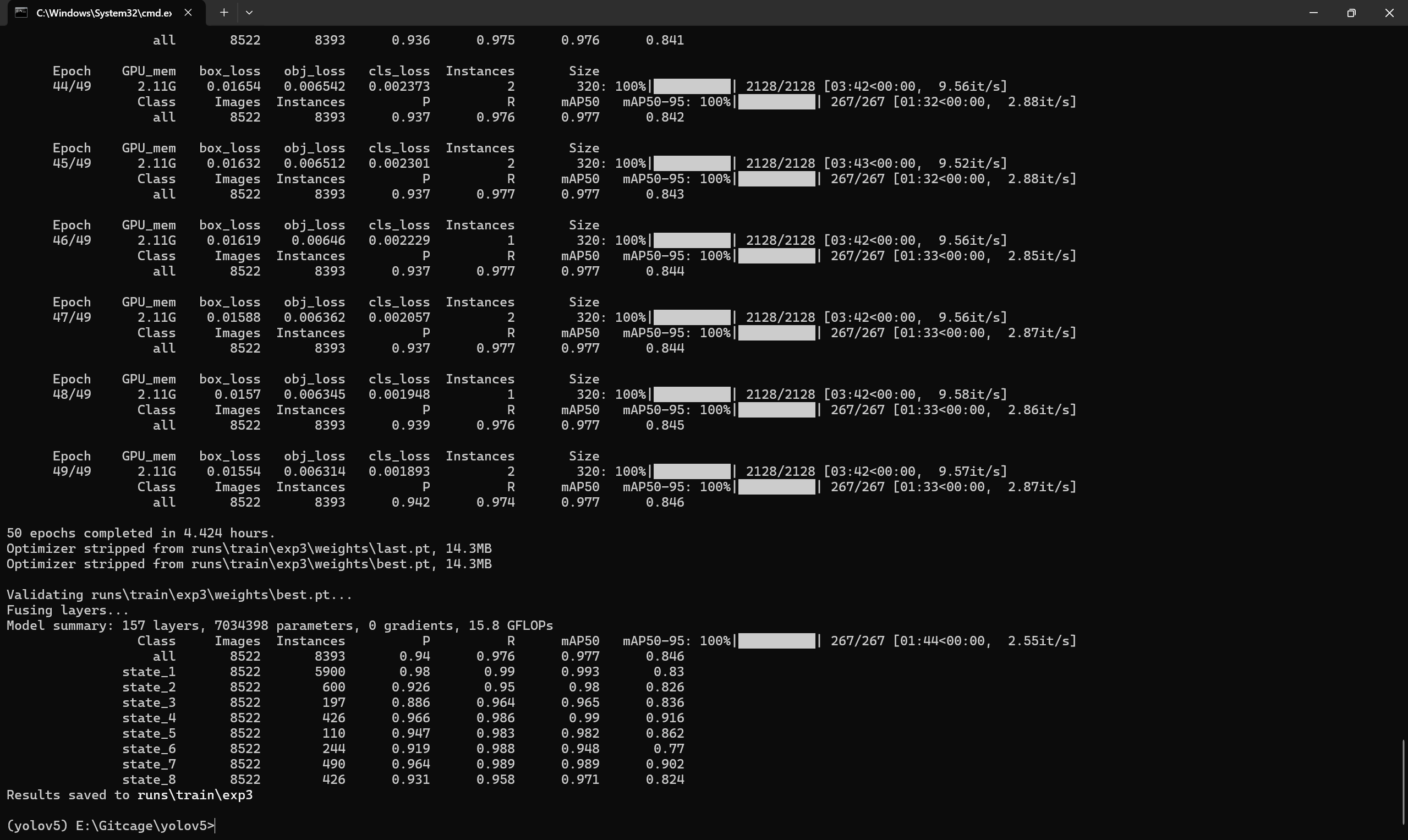
结果非常好由原来的40直接上升到90+。马上再用yolov8测试看看效果如何。
yolov8的训练结果比v5的训练结果要好一点但是不是很明显。
数据没贴上,等会训练的时候贴上。
yolo8训练
首先是训练代码
yolo detect train model=yolov8s.yaml data=bigfall.yaml epochs=50 imgsz=320 batch=16 name=bigfall_s_v2 pretrained=True device=0 |
💡 参数说明(因为你肯定忘了):
model=yolov8s.yaml:使用哪个模型结构,可以换成yolov8s.yaml、yolov8m.yaml等等。data=your_dataset.yaml:数据配置文件,别给错路径,别写错名字。epochs=100:训练 100 轮,够你煎出炼丹炉底。imgsz=640:输入图像大小。batch=16:每批处理 16 张图,没显卡别乱写。name=bigfall_s_v1:结果保存目录runs/detect/bigfall_s_v1/。pretrained=True:是否用 COCO 预训练模型打底,建议 True。device=0:用第一个 GPU。如果你根本没 GPU,那你只能 device=cpu,然后关上电脑哭去。
保存一个cmd命令,怕等会忘记,由于自身笔记本的高度太低,使用手边的rv1106的板子加上sc3336的摄像头直接架高模拟摄像头查看推理效果如何。
yolo task=detect mode=predict model=runs/detect/train/weights/best.pt data=bigfall.yaml source="rtsp://172.32.0.93/live/0" show=true conf=0.25 |
yolo task=detect mode=predict model=runs/detect/bigfall_s_v1/weights/best.pt data=bigfall.yaml source="rtsp://172.32.0.93/live/0" show=true conf=0.25 |
yolo detect train model=yolov8s.yaml data=bigfall_v3.yaml epochs=50 imgsz=320 batch=16 name=bigfall_s_v4 pretrained=True device=0 warmup_epochs=0 |
yolo detect train model=yolov8s.yaml data=bigfall_v3.yaml epochs=50 imgsz=320 batch=16 name=bigfall_s_v5 pretrained=True device=0 warmup_epochs=3 cos_lr=True |